The best kinds of classes can be built by teachers who attend to three foundational layers.
First, the layer too often taken for granted: the key beliefs that underlie behavior and effort. Specifically, these teachers understand the four components of teacher credibility — trust, competence, dynamism, and immediacy — knowing both how to build these components and how to avoid undermining them. Even more importantly, these teachers learn how to leverage their hard-earned teacher credibility toward cultivating in students the four key beliefs about school (academic mindsets). Apart from these beliefs, all our efforts in the classroom are doomed to less effectiveness than they are capable of.

This layer is important for two reasons:
1) Professional development offerings and teacher training programs tend to ignore, obscure, or over-complicate it. We neglect these things at great costs to our students and ourselves!
2) It acts as a multiplier for any curriculum or instruction that takes place on top of it. No matter how incredible the curriculum or solid the instruction, a non-credible teacher or a learning environment that crushes the academic mindsets will only produce below-average returns.
We can't stop at the first layer, of course. With the first layer in place, we've not even taught anything — all we've done is built the table upon which an education can be enjoyed.
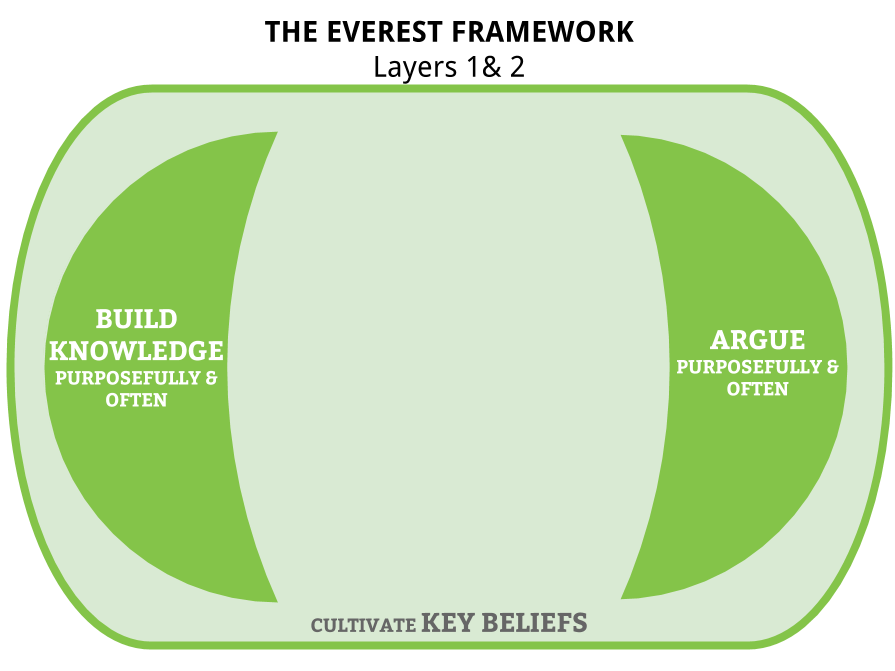
In the second layer we add knowledge and argument, the latter of which I've argued is more manageable than critical thinking. Despite the popular sentiment that we no longer need to know things — because, you know, Google — I find that students love becoming knowledgeable, and people smarter than me find that becoming a sharp thinker isn't possible without knowledge. (And while some may be content to make their students ever-dependent on Googling things, I want a bit more than that for my own children and students.) Every course will bring different answers to the following questions:
- What things are helpful to know in this course? How is this information best organized so as to aid the learner? Are their multiple ways in which learners need to access this information? (For that latter question, an example would be that in my world history courses, I want students to think of history chronologically, conceptually, thematically, and geographically.)
- What do people argue about in my discipline? How do they argue? What basic structures can my students use to practice this?
And finally, how do we have our students acquire this knowledge and build this argumentative skill? Through an abundance of purposeful reading and writing and speaking and listening. That is the third layer. Our objective with these things is to increase both the quantity and quality of literacy work our students do.
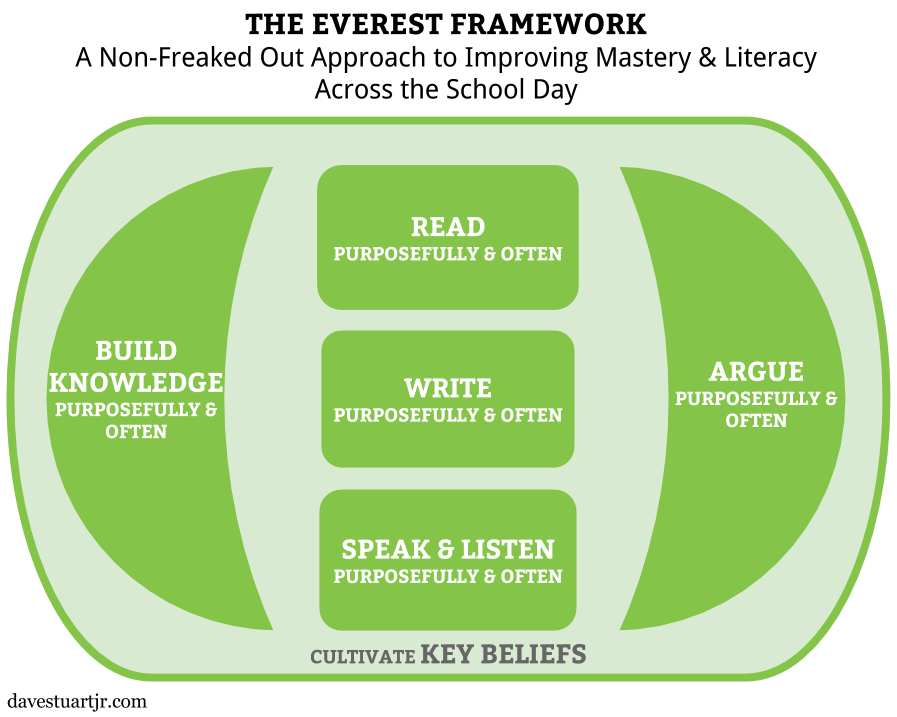
Together, these three layers are flexible enough to work across the content areas and simple enough to get us out of the hamster wheel of constant reinvention and on to the rewarding, noble pursuit of excellence in our classrooms. I think that is why teachers around the country have been encouraged and equipped by my all-day literacy workshop for secondary folks across the content areas. It makes us both better and saner, and it all adds up to the kind of work we always hoped we'd be doing when we decided to become educators.
For more information on the all-day literacy workshop that I’ve given across the USA, click here.

Lynn Kameny says
Dave, I think your graphic is great and could be even better if the non-cognitive factors were included on the graphic so they are immediately clear to the viewer. An idea: create arrows coming out from either side of “Leveraging NONCOGNITIVE Factors” and then list one non-cognitive factor in the light green space surrounding each of the dark green half moon shapes (one on each side) and list the third one at the top. Use double sided arrows to connect those 3 factors to each other. The double-sided arrows between them would then literally encircle your framework in non-cognitive factors as well as providing a foundation for them.
davestuartjr says
Lynn, this is really great feedback — THANK YOU. I’ll play around with this soon!
Savana kennedy says
Dave, can you please answer me this question. Scientists recognise them as key layers of thinking. What are they?
It’s for my course work.
Dave Stuart Jr. says
Hmm, I’m sorry Savana — I don’t know what the question is after.
Savana kennedy says
Thanks Dave, i know you gave it a try
Dave Stuart Jr. says
I really did! Take care Savana.